
Python的GIL
简介
熟悉Python的人理应都听过GIL(Global Interpreter Lock,全局解释器锁) ,大概也知道它就是造成Python多线程并发其实是「伪并行」的核心原因,但依旧很多人没有深入其中,所以HackPython尝试以上、下两篇文章来阐释GIL,分别从其表现现象、对应源码以及Python对GIL改进等方面进行讨论
Python多线程的伪并行
Python中可以使用「threading」模块来创建并使用多线程,为了直观比较,先试一下一个没有使用多线程的代码 ,如下:
1 | import time |
代码非常简单,就是一个add()方法一直做累加操作,运行结果为 :
1 | python 5.py |
那我使用多线程效果会不会好一些呢?凭感觉直观而言,应该是会的 ,因为上面的程序只使用了一个线程,那我开两个线程,让其同时工作,其运行时间应该短一半才对 ,但事实时使用多线程后,运行时间依旧没有变动 ,多线程版本的代码如下:
1 | import threading, time |
为了让相加的数量相近,这里每个线程只需要执行「n//2」次,使用join的目的是得等线程运行完后,再执行后续的逻辑,这里只是为了方便记录运行时间 。运行结果如下:
1 | python 6.py |
发现跟一开始单线程的程序在运行时间上没有什么差异,而造成这种现象的原因就是GIL ,需要注意的是,GIL只存在于通过C语言实现的Python解释器上,即CPython上 ,后人为了绕过GIL的问题利用Java开发了Jpython或使用Python自己开发了自己的解释器PyPy,这些上都不存在GIL全局解释器锁的问题 ,但CPython才是当前最多人使用的主流Python解释器 。
在CPython中,每一个Python线程执行前都需要去获得GIL锁 ,获得该锁的线程才可以执行,没有获得的只能等待 ,当具有GIL锁的线程运行完成后,其他等待的线程就会去争夺GIL锁,这就造成了,在Python中使用多线程,但同一时刻下依旧只有一个线程在运行 ,所以Python多线程其实并不是「并行」的,而是「并发」 。
看到下图,图中是Python中GIL的工作实例,其中有3个线程,线程与线程之间是顺序执行的 ,每个线程开始执行时都会去获得GIL,防止其他线程线程运行 ,每执行完一段时间后,就会释放GIL,让别的线程可以去争夺执行权限,如果自己本身也没有执行完,则本身也会参与这次争夺 。
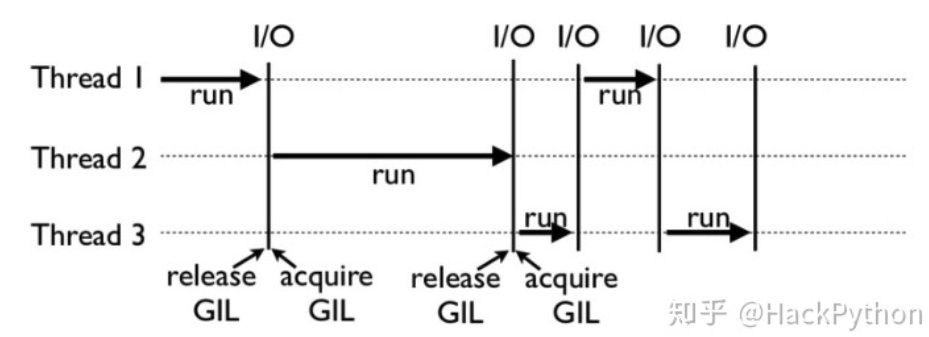
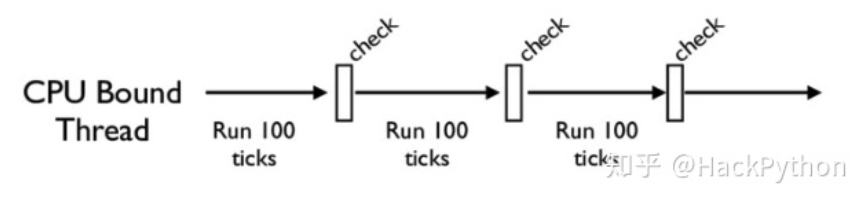
可以发现,Python中的线程工作一段时间后,会主动释放GIL,这是为了让其他线程都有机会执行 ,而释放的时机就涉及到了「检查间隔」(check interval)机制 ,在早期版本的Python中,检查机制是100ticks,而Python3后,每15毫米使用一次检查间隔,然后就会释放GIL锁 。
但需要注意的是线程有了GIL后并不意味着使用Python多线程时不需要考虑线程安全 ,「GIL的存在是为了方便使用C语言编写CPython解释器的编写者,而顶层使用Python时依旧要考虑线程安全」 ,在下一篇中会从原始编码层面来解释存在GIL后,依旧会有线程不安全现象的原因。
多进程实现并行
GIL的存在让Python多线程在运行CPU密集型性程序时显得非常无力,为了绕过GIL的限制,一种简单的方法就是使用多进程 ,这是因为GIL只会存在于线程级别,即一个进程为了确保某一时刻下只有一个线程在运行,才使用GIL ,但多个进程之间并不会出现这种限制,不同的进程会运行在CPU不同的核上,实现真正的「并行」 。
通过进程的方式将上面的任务再执行一遍,看一下运行时长,具体代码如下:
1 | from multiprocessing importProcess |
Python中多进程可以使用 multiprocessing 这个库,使用方法与使用线程类似 ,代码中启用了两个进程,分别运行 n//2 数据量的数据,其结果如下:
1 | python 7.py |
从结果可以看出,时间确实减少了一半左右,多进程状态下确实是真正的「并行」。
如何绕过GIL?
有了多进程后,大部分程序都可以通过多进程的方式绕过GIL ,但如果依旧不满足,就需要使用C/C++来实现这部分代码,并生成对应的so或dll文件,再通过Python的ctypes将其调用起来 ,Python中很多对计算性能有较高要求的库都采用了这种方式,如Numpy、Pandas等等 。
如果你对程序的性能要求的特别严格,此时更好的方法是选择其他语言 。