
BN和LN的区别
什么是Normalization
Normalization:规范化或标准化,就是把输入数据X,在输送给神经元之前先对其进行平移和伸缩变换,将X的分布规范化成在固定区间范围的标准分布
变化框架:
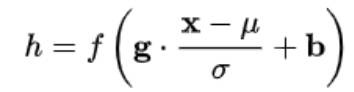
参数介绍:μ:平移参数 ,δ:缩放参数 ,b :再平移参数, g 再缩放参数,得到的数据符合均值为 b 、方差为g^2 的分布
深度学习中为什么要用Normalization?
Normalization 的作用很明显,把数据拉回标准正态分布,因为神经网络的Block大部分都是矩阵运算,一个向量经过矩阵运算后值会越来越大,为了网络的稳定性,我们需要及时把值拉回正态分布
Normalization根据标准化操作的维度不同可以分为batch Normalization和Layer Normalization,不管在哪个维度上做noramlization,本质都是为了让数据在这个维度上归一化,因为在训练过程中,上一层传递下去的值千奇百怪,什么样子的分布都有。BatchNorm就是通过对batch size这个维度(针对每个特征)归一化来让分布稳定下来。LayerNorm则是通过对每个样本这个维度归一化来让每个样本的分布稳定
BN vs LN
BatchNorm是对一个batch-size样本内的每个特征做归一化,LayerNorm是对每个样本的所有特征做归一化
BN抹杀了不同特征之间的大小关系,但是保留了不同样本间的大小关系;LN抹杀了不同样本间的大小关系,但是保留了一个样本内不同特征之间的大小关系(理解:BN对batch数据的同一特征进行标准化,变换之后,纵向来看,不同样本的同一特征仍然保留了之前的大小关系,但是横向对比样本内部的各个特征之间的大小关系不一定和变换之前一样了,因此抹杀或破坏了不同特征之间的大小关系,保留了不同样本之间的大小关系;LN对单一样本进行标准化,样本内的特征处理后原来数值大的还是相对较大,原来数值小的还是相对较小,不同特征之间的大小关系还是保留了下来,但是不同样本在各自标准化处理之后,两个样本对应位置的特征之间的大小关系将不再确定,可能和处理之前就不一样了,所以破坏了不同样本间的大小关系)
举例
假设我们有 3行 10列 的数据,即我们的batchsize = 10,每一列数据有三个特征,假设这三个特征是【身高、体重、年龄】。那么BN是针对每一行(特征)进行缩放,例如算出【身高】的均值与方差,再对身高这一行的10个数据进行缩放。体重和年龄同理。这是一种“行缩放”。而layer方向相反,它针对的是每一列进行缩放。即只看一笔数据,算出这笔所有特征的均值与方差再缩放。这是一种“列缩放”
细心的你已经看出来,layer normalization 对所有的特征进行缩放,这显得很没道理。我们算出一列这【身高、体重、年龄】三个特征的均值方差并对其进行缩放,事实上会因为特征的量纲不同而产生很大的影响。但是BN则没有这个影响,因为BN是对一行进行缩放,一行的量纲单位都是相同的
那么我们为什么还要使用LN呢?因为NLP领域中,LN更为合适
如果我们将一批文本组成一个batch,那么BN的操作方向是,对每句话的第一个词进行操作。但语言文本的复杂性是很高的,任何一个词都有可能放在初始位置,且词序可能并不影响我们对句子的理解。而BN是针对每个位置进行缩放,这不符合NLP的规律
而LN则是针对一句话进行缩放的,且LN一般用在第三维度,如[batchsize, seq_len, dims]中的dims,一般为词向量的维度,或者是RNN的输出维度等等,这一维度各个特征的量纲应该相同。因此也不会遇到上面因为特征的量纲不同而导致的缩放问题
使用场景
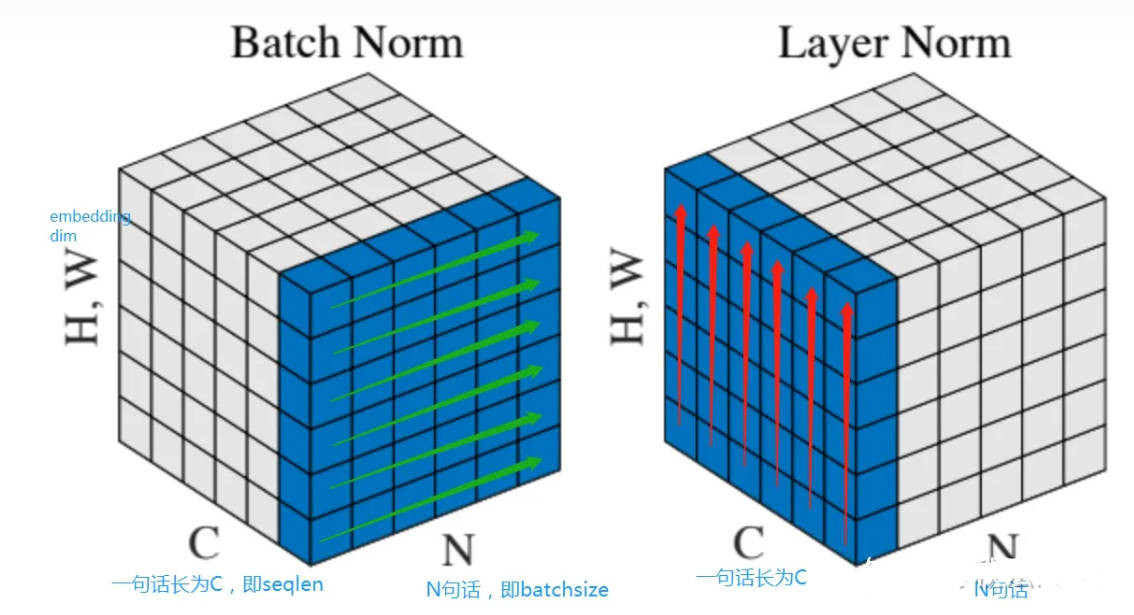
在BN和LN都能使用的场景中,BN的效果一般优于LN,原因是基于不同数据,同一特征得到的归一化特征更不容易损失信息。但是有些场景是不能使用BN的,例如batch size较小或者序列问题中可以使用LN。这也就解答了RNN 或Transformer等NLP领域为什么用Layer Normalization?