
NVIDIA GPU架构
NVIDIA GPU的架构演变历史和基本概念
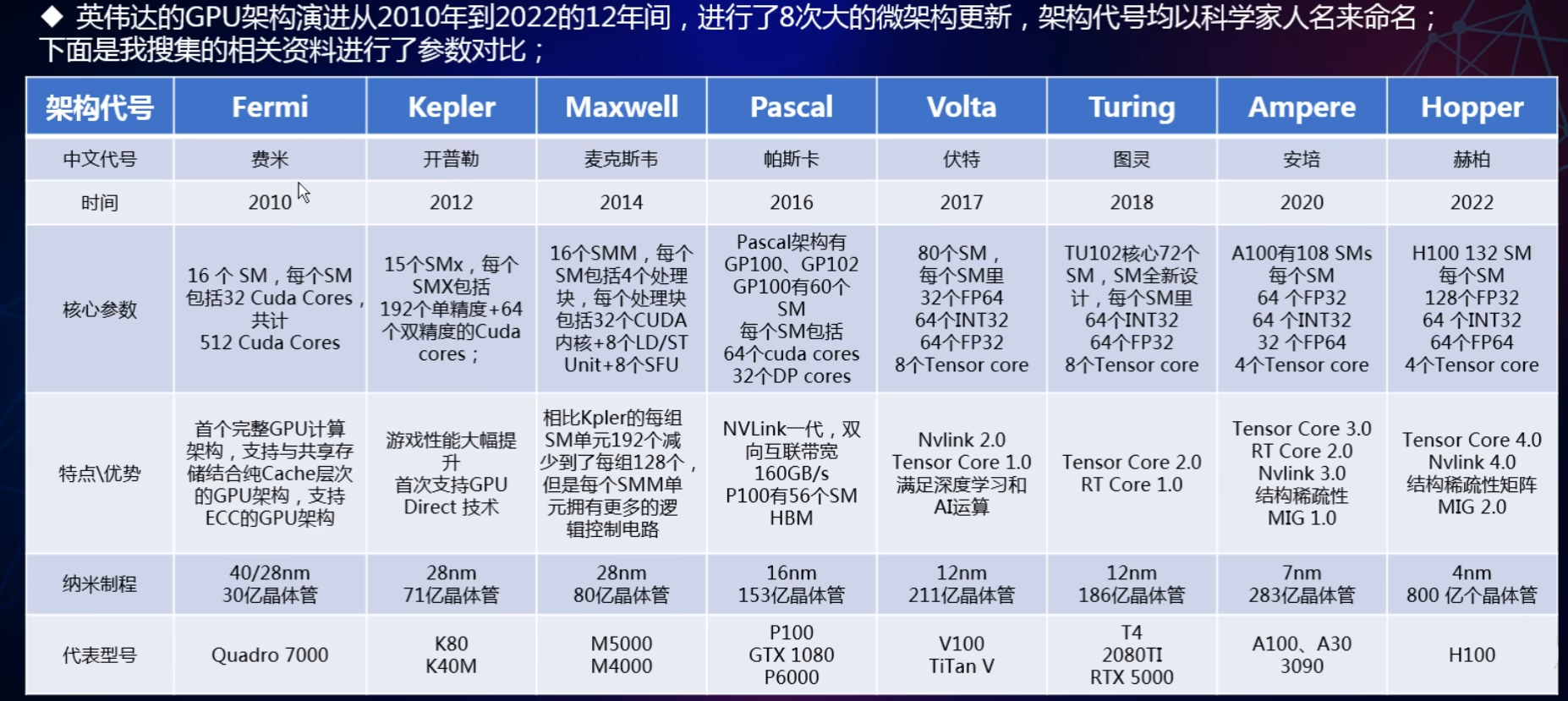
截止2021年,发布时间离我们最近的8种NVIDIA GPU微架构是:
- Tesla
- Fermi
- Kepler
- Maxwell
- Pascal
- Volta
- Turing
- Ampere
NVIDIA一般以历史上一些著名科学家的名字命名自己的GPU微架构,上面8种微架构分别是:特斯拉,费米,开普勒,麦克斯韦,帕斯卡,伏打,图灵,安培。
其中最新的是2020年宣布的Ampere架构。
Tesla 架构
Tesla 架构的资料在官网也没找到多少,不过这是英伟达第一个实现统一着色器模型的微架构。
经典型号是G80,在Fermi架构白皮书的开篇部分有对G80的简要介绍:
- G80 是第一款支持 C 语言的 GPU,让程序员无需学习新的编程语言即可使用GPU的强大功能。
- G80 是第一款用单一、统一的处理器取代独立的顶点和像素管道的 GPU,该处理器可以执行顶点、几何、像素和计算程序。
- G80 是第一款使用标量线程处理器的 GPU,无需程序员手动管理向量寄存器
- G80 引入了单指令多线程 (SIMT) 执行模型,即多个独立线程使用一条指令并发执行。
- G80 为线程间通信引入了共享内存(shared memory)和屏障同步(barrier synchronization)。
Fermi架构
Fermi 架构是NVIDIA GPU 架构自初代 G80 以来最重大的飞跃。
NVIDIA的GPU研发团队从G80和GT200两个型号上汲取经验,采用全新的设计方法来创建世界上第一个计算 GPU。在这个过程中,专注于提高以下关键领域:
- 提高双精度性能——虽然单精度浮点性能大约是桌面 CPU 性能的十倍,但一些 GPU 计算应用程序也需要更高的双精度性能。
- ECC 支持——ECC 允许 GPU 计算用户在数据中心安装中安全地部署大量 GPU,并确保医疗成像和金融期权定价等数据敏感应用程序免受内存错误的影响。
- True Cache Hierarchy—— 一些并行算法无法使用 GPU 的共享内存,用户需要一个真正的缓存架构来帮助他们。
- 更多共享内存——许多 CUDA 程序员要求超过 16 KB 的 SM 共享内存来加速他们的应用程序。
- 更快的上下文切换——用户要求在应用程序和更快的图形和计算互操作之间进行更快的上下文切换。
- 更快的原子操作(Atomic Operations)——用户要求为他们的并行算法提供更快的读-修改-写原子操作。
第一个基于Fermi架构的GPU,使用 30 亿个晶体管实现,共计512个CUDA内核。
这512 个 CUDA 内核被组织成 16 个 SM,每个 SM 是一个垂直的矩形条带,分别位于一个普通的 L2 cache周围,每个 SM 有32 个CUDA 内核。
一个CUDA 内核为一个线程在每个时钟周期里执行一条浮点或整数指令。
6个64-bit显存分区,组成一个384-bit的显存接口,总共支持高达 6GB 的 GDDR5 DRAM显存。
GDDR5:第五版图形用双倍数据传输率存储器
DRAM:动态随机存取存储器
主机接口(host interface )通过 PCI-Express 将 GPU 连接到 CPU。 Giga Thread 全局调度器将线程块分发给 SM 线程调度器。
整个 GPU 有多个 GPC(图形处理集群),单个GPC包含一个光栅引擎(Raster Engine),四个 SM(流式多处理器),GPC 可以被认为是一个独立的 GPU。所有从 Fermi 开始的 NVIDIA GPU,都有 GPC。
SM(Streaming Multiprocessors)是GPU架构中非常重要的部分,GPU硬件的并行性就是由SM决定的。
Kepler架构
Kepler架构的思路是:减少SM单元数(在这一代中叫SMX单元),增加每组SM单元中的CUDA内核数。在Kepler架构中,每个SM单元的CUDA内核数由Fermi架构的32个激增至192个。
在每个SMX中:
- 4 个 Warp Scheduler,8 个 Dispatch Unit
- 绿色:192个 CUDA 内核,分在12条 lane 上,每条分别是 16 个
- 黄色:64 个DP双精度运算单元,分在4条 lane 上,每条 lane 上 16 个
- 32 个 LD/ST Unit
- 32 个 SFU
Maxwell架构
Maxwell架构的SM单元和Kepler架构相比,又有很大变化,这一代的SM单元更像是把4个Fermi 架构的SM单元,按照2x2的方式排列在一起,这一代称为SMM单元。
SMM 使用基于象限的设计,具有四个 32 核处理块(processing blocks),每个处理块都有一个专用的 warp 调度程序,能够在每个时钟分派两条指令。
每个 SMM 单元提供
- 八个纹理单元(texture units)
- 一个多态引擎(polymorph engine-图形的几何处理)
- 专用寄存器文件和共享内存。
每个处理块中:
- 1个 Warp Scheduler,2 个 Dispatch Unit
- 绿色:32个 CUDA 内核
- 8个 LD/ST Unit
- 8个 SFU
CUDA内核总数 从Kpler时代的每组SM单元192个减少到了每组128个,但是每个SMM单元将拥有更多的逻辑控制电路,便于精确控制。
Pascal架构
这里有一个新概念:核心
NVIDIA不同的架构会有几种不同的核心,Pascal架构有GP100、GP102两种大核心:
- GP100:3840个CUDA核心,60组SM单元;
- GP102:3584个CUDA核心,28组SM单元;
第2组数据存疑
核心是一个完整的GPU模组,上图展示了一个pascal架构的GP100核心,带有 60 个 SM 单元。
不同的显卡产品可以使用不同的 GP100 配置,一般是满配或者减配,比如Tesla P100 使用了 56 个 SM 单元。
每个SM单元中,分为2个Process Block,每个Process Block中:
- 1个 Warp Scheduler,2 个 Dispatch Unit
- 绿色:32个 CUDA 内核
- 黄色:16 个DP双精度运算单元,分在2条 lane 上,每条 lane 上 8个
- 8个 LD/ST Unit
- 8个 SFU
CUDA内核总数从Maxwell时代的每组SM单元128个减少到了每组64个,这一代最大的特点是又把DP双精度运算单元加回来了。
制程工艺升级到了16nm,性能大幅提升,功耗却不增加。
Volta架构
每个SM单元中,分为4个Process Block,每个Process Block中:
- 1个 Warp Scheduler,1个 Dispatch Unit
- 8 个 FP64 Core
- 16 个 INT32 Core
- 16 个 FP32 Core
- 2 个 Tensor Core
- 8个 LD/ST Unit
- 4个 SFU
在前几代架构中:
一个CUDA 内核在每个时钟周期里只能为一个线程执行一条浮点或整数指令。
但是从Volta架构开始,将一个CUDA 内核拆分为两部分:FP32 和 INT32,好处是在同一个时钟周期里,可以同时执行浮点和整数指令,提高计算速度。
Volta架构在传统的单双精度计算之外还增加了专用的Tensor Core张量单元,用于深度学习、AI运算等。
Turing架构
Turing架构目前一共有三种核心:
- TU102核心
- TU104核心
- TU106核心
每个SM单元有4个处理块,每个处理块中:
- 1 个 Warp Scheduler,1 个 Dispath Unit
- 16 个 INT32 Core
- 16 个 FP32 Core
- 2 个 Tensor Core
- 4 个 LD/ST Unit
- 4 个 SFU
这一代架构去掉了对FP64的支持。
Ampere架构
每个SM单元分成4个处理块,每个处理块中:
- 1 个 Warp Scheduler,1 个 Dispatch Unit
- 8 个 FP64 Core
- 16 个 FP32 Core
- 16 个 INT32 Core
- 1 个 Tensor Core
- 8 个 LD/ST Unit
- 4 个 SFU
这一代架构又把FP64 Core加回来了,同时也是自Volta架构以来的,NVIDIA第三代Tensor技术,保持一代架构更新一次Tensor。